Specification export based on Microsoft Word Template(November update)
This is an old feature which we are not actively supporting anymore and some screenshots and videos below might be out of date.
The procedure can still be used to have more control while exporting project data into Word documents.
Before using the procedure below please consider using our inbuilt Doument Export functionality. We are happy to assist you on our inbuilt Exporter under our Altium Support Page.
Taking advantage of the Requirements and Systems Portal’s Python & Rest API that allows complete access to all data and combining it with the Merge Fields functionality of Microsoft Word there is a one-click functionality to export your Requirements Specifications into a Word document. This functionality gives you the opportunity to choose which requirement fields you want to include in your document and how to place them.
Merge Fields and Templates
Merge Fields are used as a reference to a data field by their name. When a template document is mail merged with the values from a data source, the data field information replaces the merge field.
By creating a template document with different Merge fields it’s possible to quickly generate the same type of output document (specifications or others) based on them.
Create a new merge field
Open the document you want to edit and go to the
Inserttab.Open the
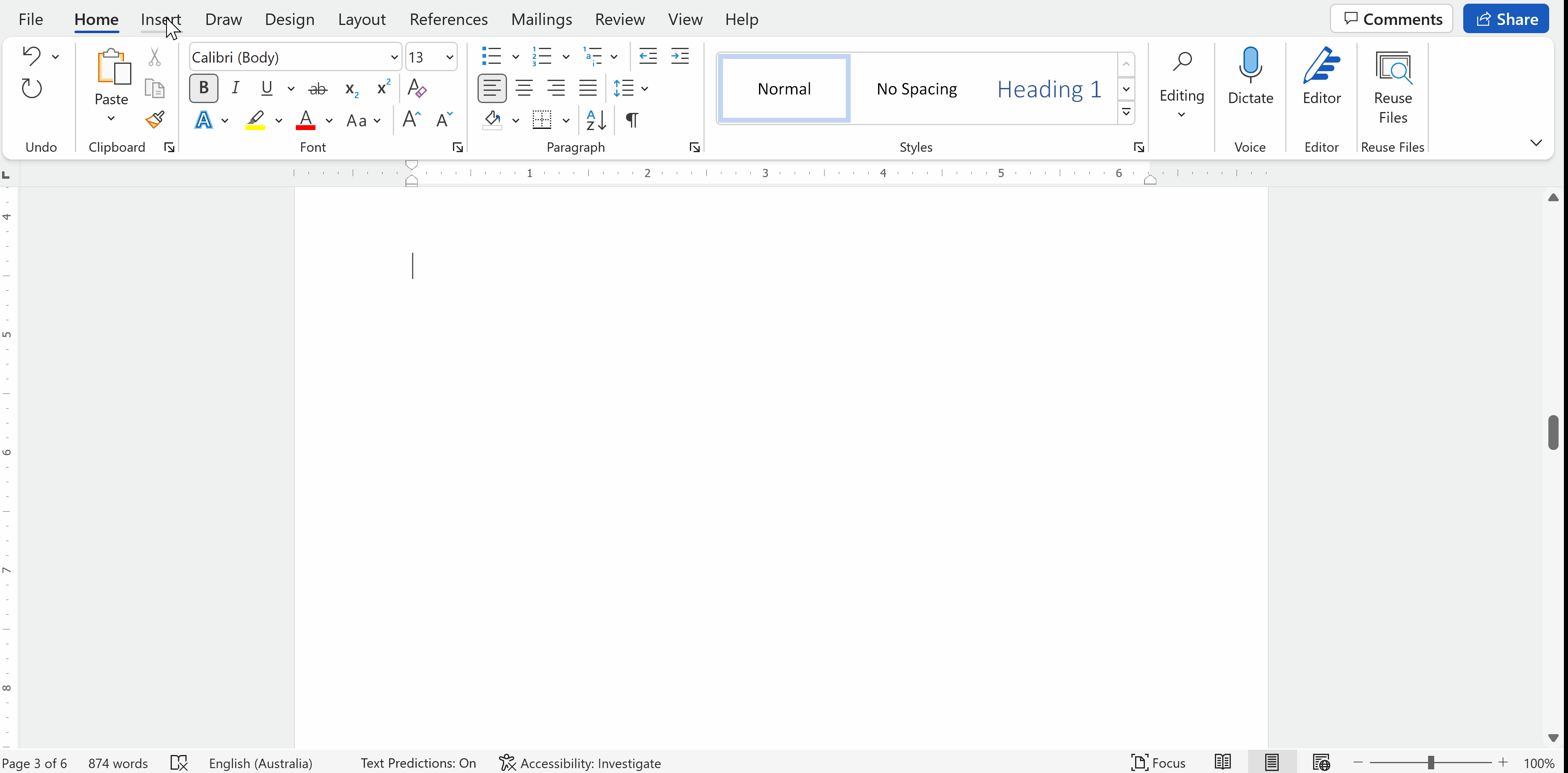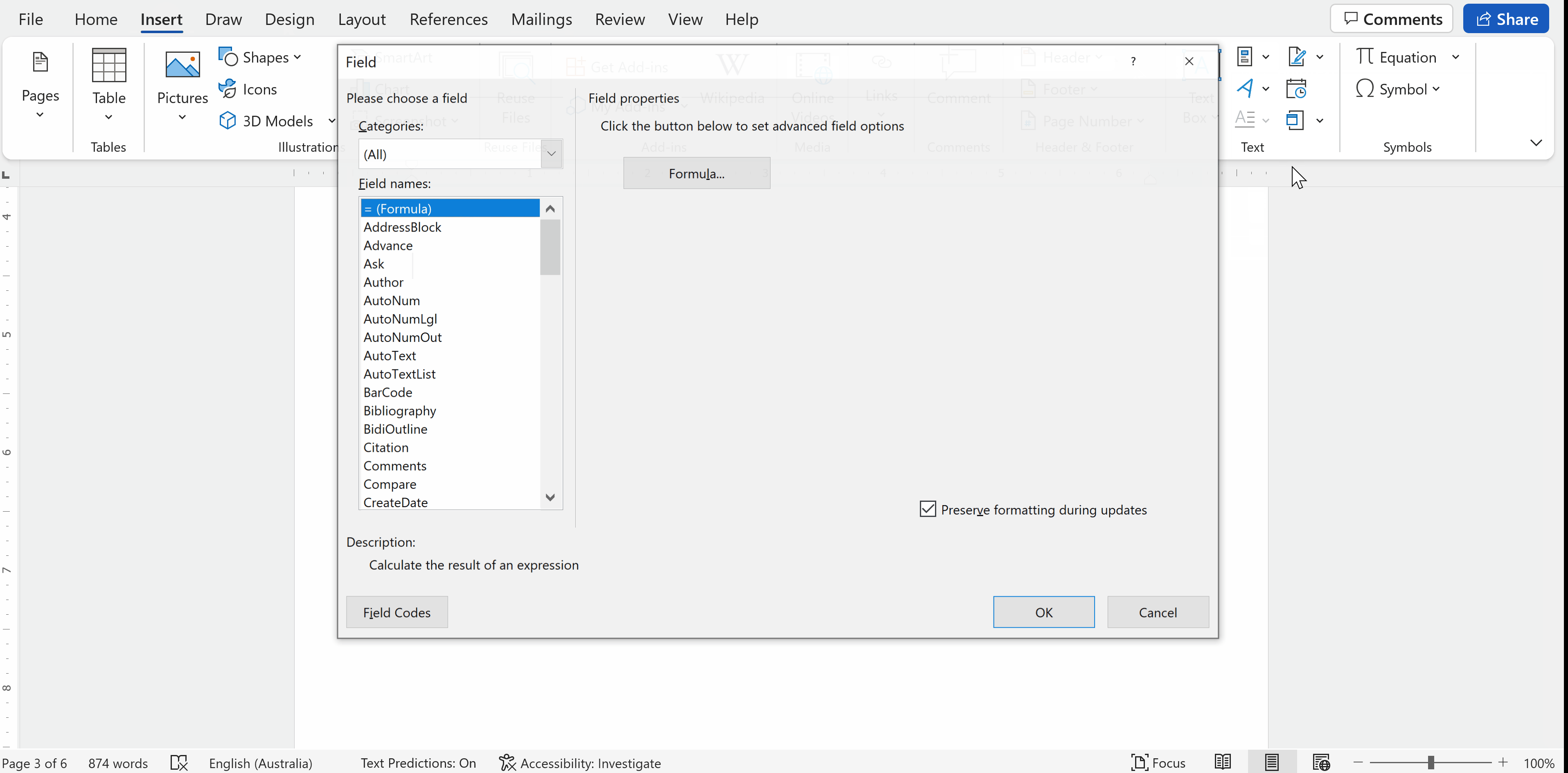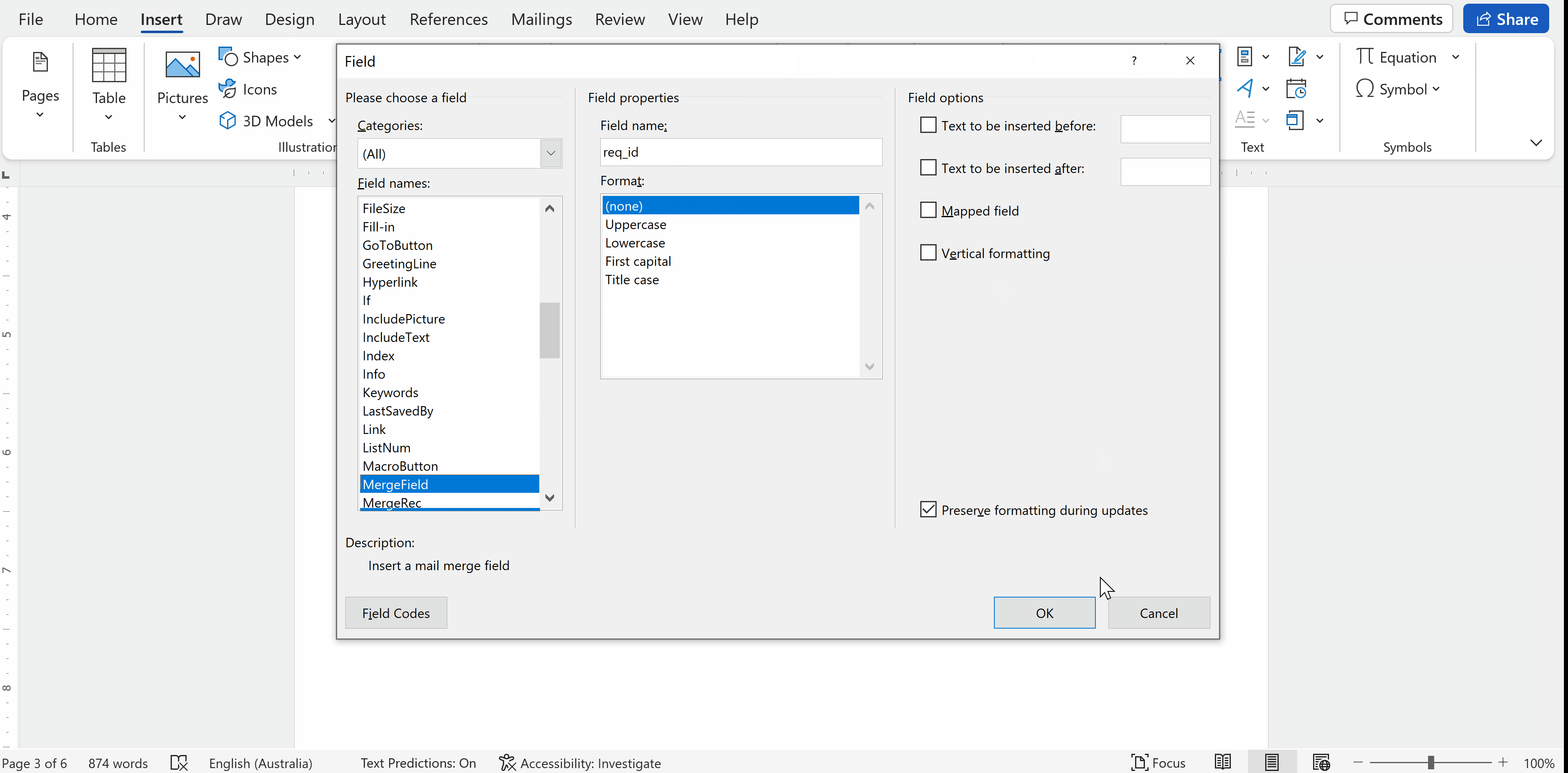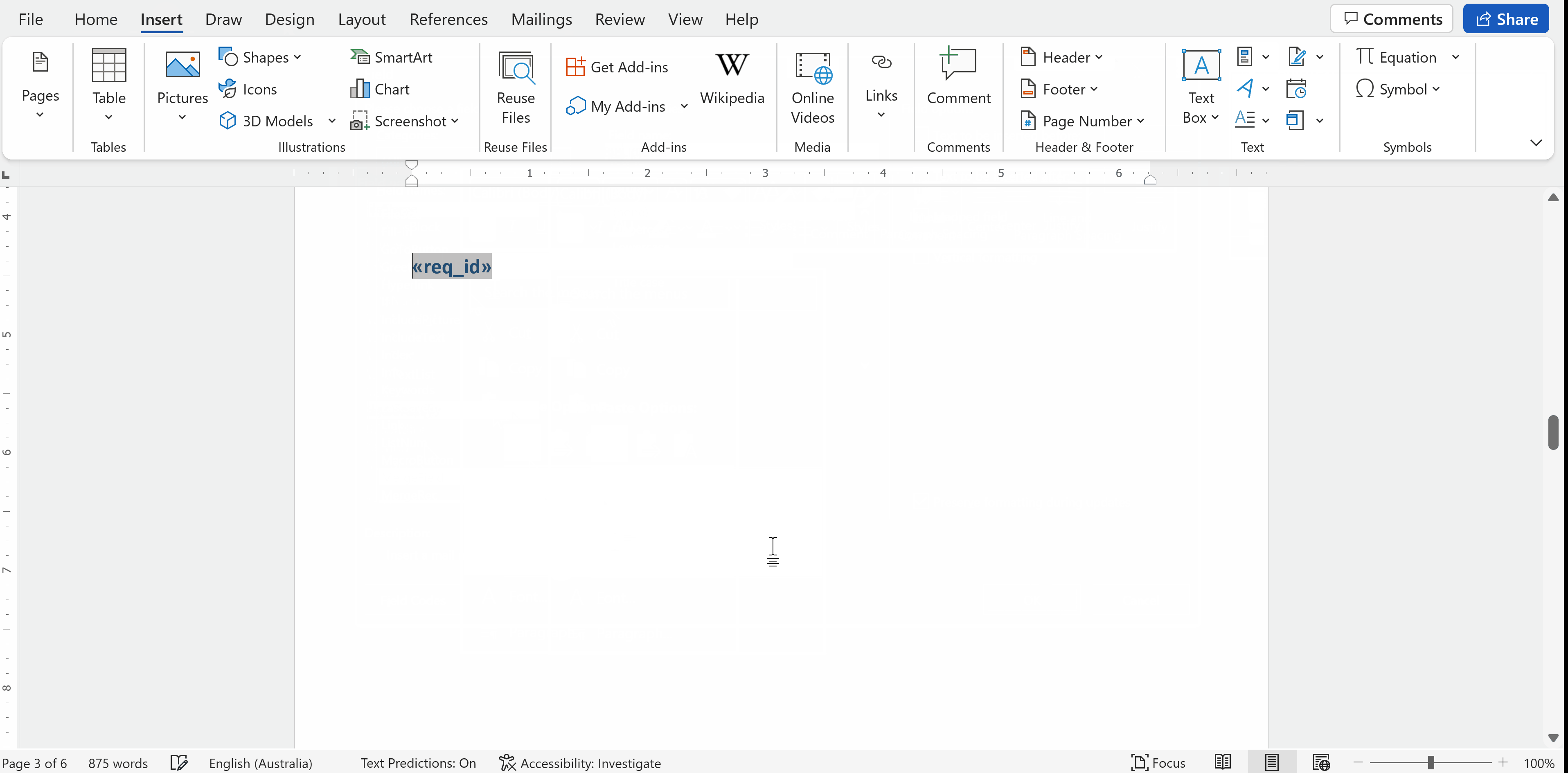
Quick Partdmenu and selectField. TheFielddialog window will open.In the field dialog menu, choose
Merge Fieldfrom the list on the left side. Enter the merge field name in theField nametext box on the right side and clickOK.
Hint: Name the field based on the data you want it to be replaced for to be easier to trackThe merge field is inserted in the Word file. The object should be highlighted in grey if you click on it.
The merged fields that have corresponding Python functions already defined are:
«req_id» - Requirement Identifier
«req_title» - Requirement Tittle
«req_text» - Requirement Text
«req_state» - Requirement State
«req_type» - Requirement Type
«req_rationale» – The Rationale associated to a Requirement
«images» – The images attached to a Requirement
«specification_name» - Specification that contains the Requirement
«section_name» - Section that contains the requirement
«req_compliance» - Requirements’ Compliance statement(s)
«req_comp_comment» - Requirements’ Compliance comments
«req_owner» - Requirements’ Owner
«req_applicability» - Requirements’ Applicability
«req_ver_methods» - Requirements’ Verification Methods
«req_ver_m_text» - Requirements’ Verification Methods comments
«req_ver_closeout_ref» - Requirements’ Verification Methods Closeout References
«req_ver_status» - Requirements’ Verification Methods StatusThere is a possibility to add an URL to these fields, per example, to have an URL in the “Requirement Identifier” pointing to the requirement’s location in the Requirements and Systems Portal.
Creating Templates (for Template Replication)
A combination of Merge Fields can be used to create the template files that will be used to generate the Specification documents.
An example of a template is shown below where some fields are written on “plain text” and others as part of a table. This example is the base example for the Python scripts that will be described in the following section.
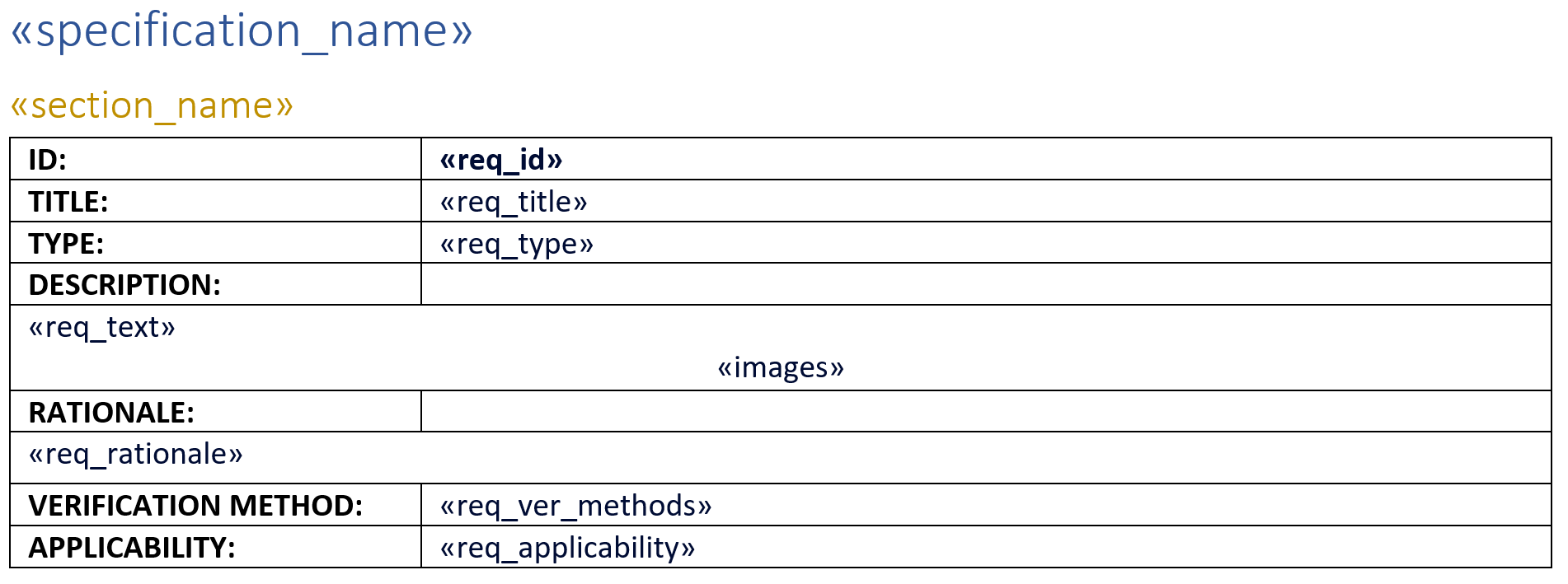
Currently the Generic Template and Generic Script are prepared to populate the Specification documents by replicating the template for each requirement but there is a possibility to populate the template one single time or , for tables, with multiple-lines per table (similar to the Requirements and Systems Portal tables or more traditional Excel tables)
If you define different Styles for each Merge Field then you can change them on the final document and the change will be reflected in the entire document. Per example defining a style for Requirement Identifier will be applied to all requirements in the final document.
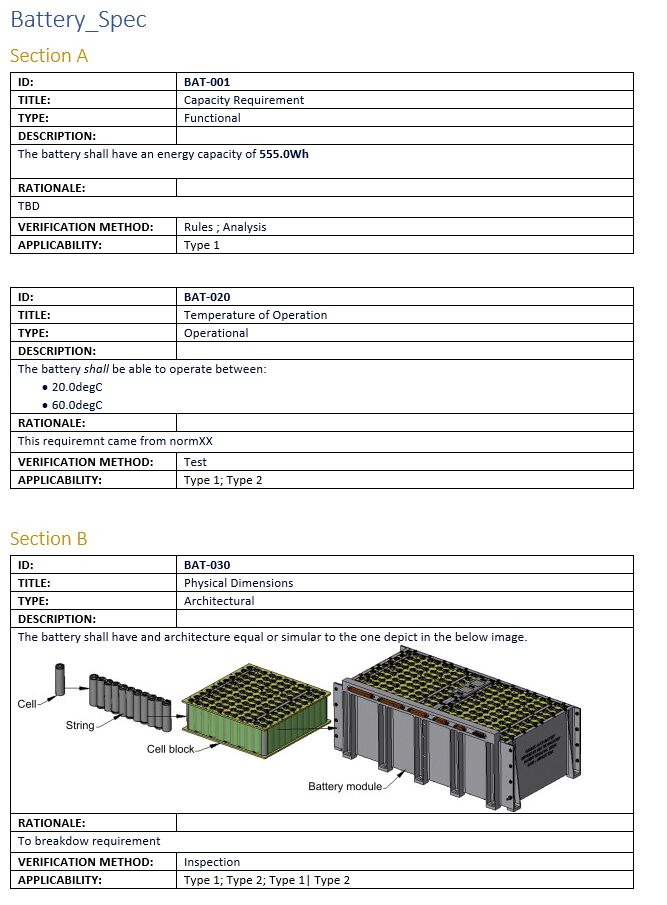
The resulting output of this template would look similar to the below picture
Python Script to populate the Template
The Python script that is used to generate documents based on a template populated with merge fields resides in the usage of the following main packages:
valispace- The Requirements and Systems Portal python API lets you access and update objects in your Requirements and Systems Portal deployment.docx-mailmerge2- Performs a Mail Merge (replaces the merge fields with desired data) on Office Open XML (Docx) files and can be used on any system without having to install Microsoft Office Word.python-docx- Python library for creating and updating Microsoft Word (.docx) files.htmldocx- Python library to convert HTML to Docx. Used to keep the format from the Requirements and Systems Portal to Word (Bold, Italic, Bullet Points…)
The code is split into 3 types of functions:
Master functions- Composed of themainandcreate_specification_documentfunctions that have the logic to export the requirements into the final document by populating the given templateRequirement data extract functions- Are all the functions to extract the requirement data such as requirement type, state, images…Document "Format" functions- Functions that perform formatting such as white space removal, ensuring tables don’t break across on the final generated document
In the following subchapter, we briefly explain these functions.
Master Functions - Main
This function allows the user to insert the domain name, its username and password, the project identifier o generate the specifications from and the path to the Template file
Then it will use this information to:
Login to the Requirements and Systems Portal using the Python API;
Download project generic data such as specifications, images, requirement types, and others;
Call the function
create_specification_documentfor each specification in the selected project.
Master Functions - Create_specification_document
The functions will create generate the specifications file by populating the Merge Fields on the template with the corresponding requirement data.
Initially, all requirements for the selected specification need to be collected:
all_specification_requirements = get_map(api, f"requirements/complete/?project="+str(DEFAULT_VALUES["project"])+"&clean_html=text&clean_text=comment", "id", None, filter_specification)
if len(all_specification_requirements) <1:
print("No requirements for Specification -> "+ specification_data['name'])
returnThen it will organize the requirements data per section, starting by the requirements without any section.
To get these non-section requirements the support function get_requirements_without_sectionis used to filter for all specification requirements that don’t have a group (how sections are stored in the Requirements and Systems Portal's backend) and sort the alphabetically.
#1st we will add requirements without section to the document
no_section_requirements = get_requirements_without_section(all_specification_requirements)Now that all non-section requirements are gathered it’s time to prepare the data that will populate the merge fields. This data is retrieved with the help of the Requirement data extract functions and will be stored in the python list as shown in the code below.
template_data.append({
"specification_name" : CURRENT_SPECIFICATION["name"] if counter == 1 else "",
"section_name" : "",
"req_id" : reqdata['identifier'],
"req_title" : reqdata['title'],
"req_text" : reqdata['identifier']+"_docx",
"req_type" : req_type,
"req_rationale" : reqdata['comment'],
"req_ver_methods" : req_vms,
"req_applicability" : req_applicability,
"images" : "Images_Placeholder_"+str(requirement) if requirement_with_images == True else "No_Images"
})For the majority of the Merged fields the data is mapped directly but for imagesandreq_textthe data will be merged at a later stage:
For
imagesa flag indicating if the requirement has images or not it stored as dataFor
req_texta placeholder is stored as data. This placeholder will also be used as a Key in a List that contains the result of parsing the requirement text from HTML to the Word as shown in the below codeCODEdocx_list[reqdata['identifier']+"_docx"] = new_parser.parse_html_string(reqdata['text'])
The same process will be repeated for the requirements that have sections and once that is done the data will be merged into the template fields and stored as a new file:
document.merge_templates(template_data, separator='continuous_section')
document.write(OUTPUT_FILE)Finally, we will use the Document "Format" functions to finalize the document by removing empty sections, and empty headings, keeping tables on one page, inserting the formatted text of requirements and their images into the document
document2 = Document(OUTPUT_FILE)
remove_all_but_last_section(document2)
remove_all_empty_headings(document2)
put_html_text(document2, docx_list)
put_images(document2, all_project_images)
keep_tables_on_one_page(document2)
document2.save(OUTPUT_FILE)
print ("Specification document created -> "+ specification_data['name'])Requirement data extract functions
The functions available to extract data from requirements are the following:
get_requirements_without_section- Returns a sorted list of all requirements without sectionget_specification_sections- Returns a list of all sections of the given specificationget_section_requirements- Returns a sorted list of all requirements of the given sectionget_requirement_images- Returns an array of all requirement imagesget_requirement_type- Returns the name of the requirement Typeget_requirement_state- Returns the name of the requirement Stateget_requirement_owner- Returns the User Groups and the First and Last name of the requirement Ownerget_requirement_applicability- Returns a list of all requirement applicable Block Types, split by a “;”get_requirement_verification_methods- Returns the name of all requirement Verification Methods, split by a “;”get_requirement_verification_methods_newline- Returns the name of all requirement Verification Methods, split by a newlineget_requirement_verification_methods_comments- Returns all requirement Verification Methods comments, split by double-newlineget_requirement_verification_status- Returns the status of all requirement Verification Methods, split by a “;”get_requirement_verification_closeout_refs- Returns the closeout references names for each requirement Verification Methods, split by a “;”get_requirement_attachments_references- Returns the name of all requirement attachments, split by a “;”get_requirement_custom_field- Returns the value of a specific Custom Field on the requirement that is passed as an argument to the function
Document "Format" functions
The functions used to format the final document are the following:
keep_tables_on_one_page- It formats the final document to not allow tables to have cell content across different pages.remove_all_empty_headings- It formats the final document to remove all empty headingsremove_all_but_last_section- It formats the final document to have only one section instead of multipleput_images- It replaces the images placeholder with the images of each requirementclone_run_props- auxiliary function to copy the properties of a run to another (used to copy HTML formatted text properties)put_html_text- It replaces the requirement text placeholder with the corresponding formatted text, such as Bold, Italic, Underline, Strikethrough and Bullet Points
Download the latest Generic Template, Python Script or Executable
Generic Specification Creation Nov2023.py Generic Specification Template.docx requirements.txt
The users can run the python script within the “Scripting module” of the Requirements and Systems Portal. Copy the code from the .py file and paste in a new python script in the scripting module.
The script can copy the tables within the requriement text as well along with the formats used in the text.
Things to edit before Running the script:
The complete procedure on how to run this code from create the scripts to generating the document have been illustrated in this video below (No audio).
Line 27 - Line 30 The user needs to define the Username and Password for the script to run. The user can use the secret managment and run the script or directly input the Username and Password in the script. However, the password will be visible to all the users within the deployment. Therefore, We would recommend you to use the “Secrets Management”.
Line 31 Copy the name of the specification and input in this line.
Line 32 Upload the Generic specification template to the file management and copy its “ID” and add it in this line.
Line 33 Add the “ID” of the project where the specification is.
Line 34 You can provide a name to the exported document.
In case you need guidance on changing the template, extracting other information to populate your templates or any question related to this feature, please feel free to send us your questions/requests via our Altium Support Page.